
How to start a reliability program when you are already 100% busy

Reliability maintenance is experiencing more management-level awareness than ever before. But even with increased support, starting a reliability program can be daunting.
Experts John Bernet and Dries Van Loon of Fluke Reliability have spent years advising maintenance teams on how to start and sustain successful reliability programs. In their webinar, “Proactive maintenance strategies to extend the life of your assets,” Bernet and Van Loon team up to offer advice for sites at the beginning of their reliability journey.
With greater data sophistication at plants has come better visibility into how maintenance operations affect overall plant outcomes. As Van Loon, the online condition monitoring sales and project manager for Fluke Reliability’s PRUFTECHNIK unit, says, “Maintenance teams now have a seat at the table, they’re no longer stuck out in a shack at the back of the plant.” Increased uptime and decreased downtime-associated costs are important metrics to monitor and talk to internally.
So, how can maintenance teams convert that uptime interest into a reliability program? Bernet, mechanical application reliability specialist at Fluke, and Van Loon advise a holistic approach of people, processes, and technology. They’ve seen enough technology-centric pilots stall out to know that changes at the team and process levels are required if reliability is going to “stick.” Figure 1 summarizes their recommendations.
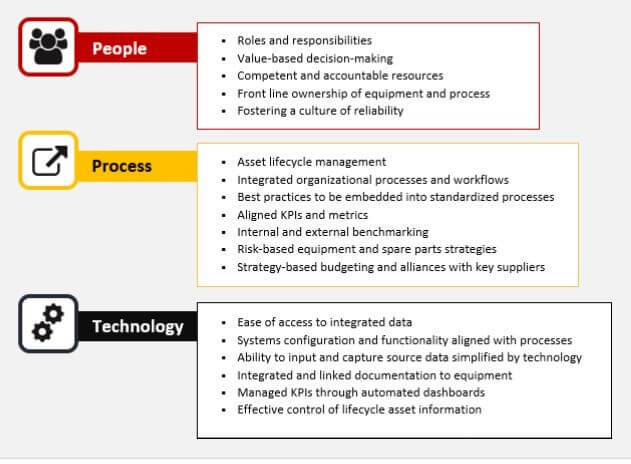 Figure 1. Attributes of successful reliability programs across three core areas: People, Processes, and Technology.
Figure 1. Attributes of successful reliability programs across three core areas: People, Processes, and Technology.
The next question people usually ask Bernet and Van Loon is “how do we monitor all of our critical assets with limited resources?” Bernet offers three key pitfalls to avoid:
- Starting too big
- Using one tool to measure everything
- Data overload
He also suggests staying away from force-ranking asset criticality, as you’ll still wind up with an overly long to-do list and not enough skilled team members to meet the objective.
For teams just starting their reliability journey, Bernet strongly recommends a tiered maintenance approach, like a hospital would use. Nurses and general practice doctors see far more patients than specialists, he says, so don’t assume that you have to have a lot of reliability experts to get the job done.
Instead, empower your technicians with training, thoughtful assignments and screening-level technology so they can be the eyes and ears of your more experienced staff. Technicians and sensors can gather much of the asset health data needed to catch machine degradation in its early stages.
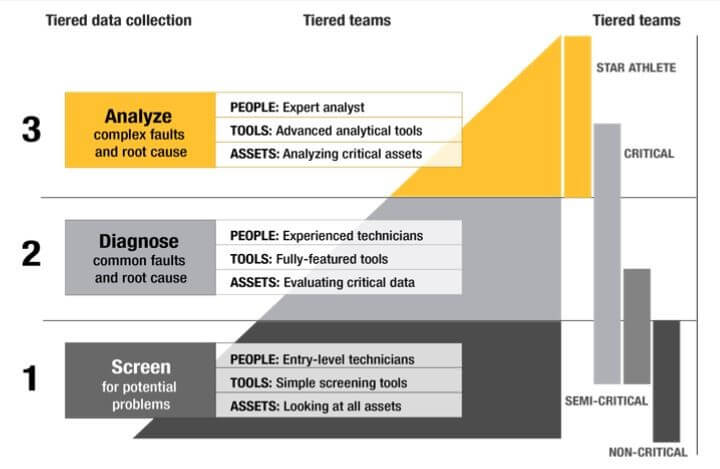 Figure 2. A “tiered maintenance” approach makes the best use of the team and technology, grows capabilities, and covers more assets.
Figure 2. A “tiered maintenance” approach makes the best use of the team and technology, grows capabilities, and covers more assets.
A team using the type of tiered maintenance depicted in Figure 2 does still require some staff with reliability expertise: to assess asset criticality, determine the inspection points, train the team, and assess the incoming data. During the webinar, Bernet has crucial advice for those who are short staffed about how to bridge the skills gap, including workflow examples and asset classification strategies.
Bernet and Van Loon also advise against simply buying a test tool and starting to measure. Busy teams won’t be able to stay on top of their asset health status long-term if they have to manually collate information from multiple sources. To avoid having the project fizzle out, Van Loon recommends creating a connected “ecosystem” of tools, asset health data, software, and services.
“Condition monitoring data, by itself, is incomplete,” Van Loon says. “It doesn’t know when an asset was last serviced, or what actions were performed, or when maintenance is next due. It doesn’t know the asset’s history of failure, what parts are needed to complete specific jobs, and whether those parts are on hand.”
You are far better off uniting real-time condition data and ongoing inspection results with your EAM or CMMS, where your other asset history and descriptive information is kept. Some solutions now offer the ability to send measurements directly from the test tool or sensor into the asset management log file. This has the added benefit of reducing the likelihood of errors.
Naturally, a lot of questions arise about what specific measurements to take on which assets and how to interpret the data. For that very reason, the ecosystem should include access to reliability experts and trainers to help design the processes, assist the analysis, and prevent the program from stalling out.
In the webinar, Van Loon reviews various categories of reliability inspection tools and technologies and offers guidance on where and when to consider using them. Like Bernet, he advises aligning the sophistication of the tool with the user’s skill level. “You need a tool that is right for the person using it and for the asset situation at hand,” he says.
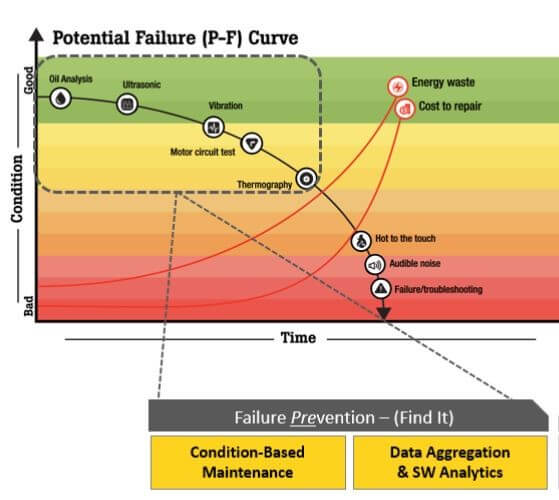 Figure 3. Use the P-F curve and asset failure-modes to determine which type of measurement to use.
Figure 3. Use the P-F curve and asset failure-modes to determine which type of measurement to use.
Successful reliability programs use a mix of proactive measurements, just as the P-F curve in Figure 3 suggests. Depending on the type and age of the assets and their operation, you may use a combination of oil analysis, ultrasound, vibration, infrared thermography, and electrical testing. Evaluate the failure modes of each critical asset and back that out along the curve to create an inspection plan.
Having measurements flow automatically into a CMMS or EAM is a relatively new capability and Van Loon spends time at the end of the webinar explaining how it works. His core message is to set your goals and work backward, keeping your desired results in mind. Start small and gradually increase the number of assets and measurements as time and skills allow. Celebrate the wins and continue communicating the core principles of reliability maintenance.
Additional resources:
Listen to the webinar presentation by John Bernet and Dries Van Loon of Fluke Reliability.
Learn about the Fluke Connected Reliability ecosystem of connected tools, software, and people.





